
GPU全名為Graphics Processing Unit (圖像處理器),由於在電腦或是嵌入式系統上,
圖檔是一個龐大資料量的檔案,若交由CPU來負責繪圖到螢幕上呈現的話,效率會非常地差,
因此就產生了GPU這樣的處理器。
那麼GPU和CPU到底差異在哪裡呢? 最主要的差異在於核心數量,一個系統上,CPU可能只有幾顆或幾十顆核心,
而GPU可達上百上千顆核心。雖然GPU擁有大量的核心,但無法執行複雜的計算,因為它最主要的用途就是將大量的資料繪製出來,
因此不需要複雜的邏輯計算單元,而這就是它與CPU硬體上的最大的不同,因為用途不同,而在硬體設計上有所差異。
OpenGL的GLSL可以實現GPU Shader簡單的繪圖計算。
大多數的人可能較常聽見的是用於PC的GPU品牌,像是Nvidia或是AMD之類的。而在嵌入式系統中, 市佔率由大到小分別是ARM、Imagination、Vivante (現已被Verisilicon收購)。
在IC設計中,通常不會只有看IP的效能(Performance),而是較全面的PPA,分別為Performance(效能)、Power(功耗)和Area(面積)。
關於GPU的PPA議題,這有點難以描述的,但可以簡單地劃分為三個角度。第一是GPU製造商廣告或業務宣稱的PPA,
由於製造商去賣產品的決不會是工程師,所以有可能業務與客戶之間在討論PPA時會出現錯誤資訊,嚴重者甚至會被視為廣告不實。
第二是硬體本身的設計,也就是IP最真實的PPA。第三是IC設計的結果,除了得看IC Designer的能力之外,最主要就是公司規劃的Spec。
照理來說,PPA的議題應該只存在第二和第三個,而第一個是不應該存在的,但就我個人的經驗來說,這是以前廠商業務常出現的問題,因此特別提出。
在IC設計這個環節,公司買進來的像是CPU、GPU、BUS、DRAM等等的元件,稱之為IP(Intellectual Property)。
而在電路設計中,每個IP都有基本的供電和資料量的需求,這又可稱之為Clock Frequency(時脈頻率),當外部供應了這個基本需求後,就可達到IP的基本效能表現。
而當供電和供應的資料量超過IP的基本標準時,這就稱之為Overclocking(超頻),雖然它可以擁有更強的效能表現,
但也伴隨著負面效應,除了會更耗電之外,也因為長時間更大的耗電而導致過熱,消耗的即是硬體的壽命,嚴重的可能產生不預期的危險情況。
每個IP之間的聯繫,是由一個重要的IP來負責,那就是BUS(資料匯流排),如下圖示:
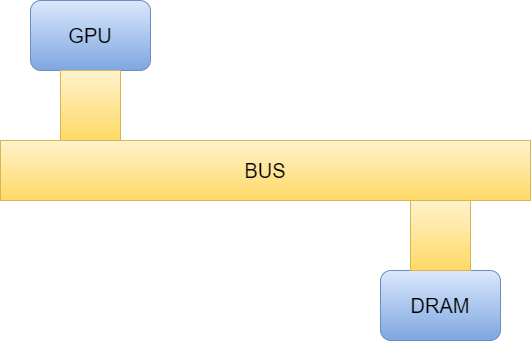
GPU到DRAM去讀寫資料的速度,除了取決於每個IP的Clock Frequency之外,還有GPU到DRAM的距離,因此若硬體佔用面積越大,
就會造成彼此間的距離增加,這個就是前面所說PPA的Area。
每個IP聯繫起來之後,就會彼此相互影響。如前面所述,每個IP可能因為商業溝通上的問題,導致IP或甚至整個IC在效能表現上不符合預期,
例如IP硬體內部設計的因素,導致外部給予的Clock Frequency,到了內部都會被砍半,例如下圖:
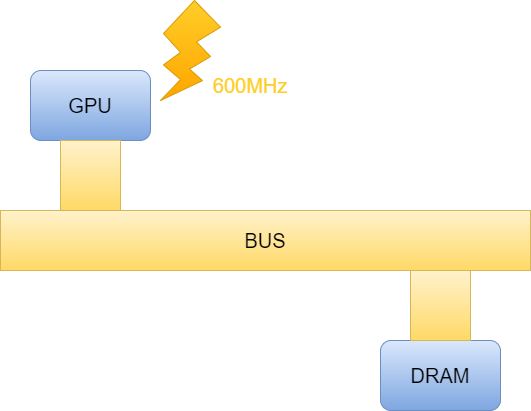
當外部給予600MHz的Clock Frequency,到了GPU內部變成了300MHz,需要特定的條件才能達到600MHz,因此這也不算是廣告不實,
只能說製造商的廣告包裝得很好,這往往也是為什麼製造商可以壓低價錢販賣IP的原因,這是我真實遇過的案例。
除了GPU可能有潛在的內部問題之外,還有什麼因素會導致效能變差呢? BUS也是一個重要因素,如前面所述,BUS本身也是一個IP,
而連接到這個BUS上的電路也都是影響因子,例如下圖:
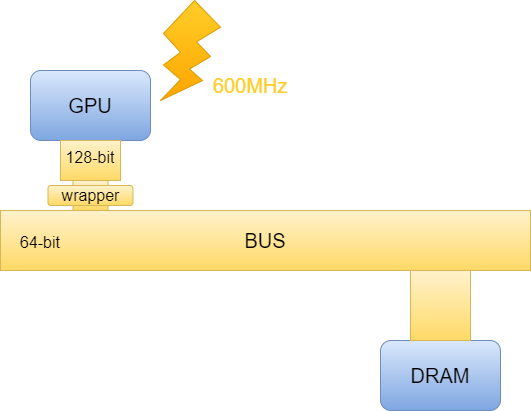
當GPU的Bandwidth(頻寬)有128 bit,但BUS卻只有64 bit的頻寬時,這時就需要有一層轉換,而這層轉換稱為Wrapper。前面提到的Overclocking(超頻),是我們給予超過IP基本需求時,可以產出超過IP的標準效能,
但是有Wrapper這樣的角色存在時,會導致不管是超頻或是不超頻的情況下,都會讓效能卡在一個階段就停止了。
那如果把BUS的頻寬也改成128 bit不就解決了嗎? 當然這是一個方法,但這就會讓整個IC的成本也跟著提升了,成本提升就無法發揮Cost Down的商業競爭策略。
除此之外,還有需要考量的也是Bandwidth延伸出來的問題。如一開始所提到的,現在的圖檔隨著解析度越來越高,資料量越來越大,Bandwidth是沒辦法承載這樣的資料量的,因此在GPU產出的時候,
都會進行壓縮,讓BUS的Bandwidth不被GPU佔滿,否則其他的IP都會被癱瘓掉。
現在問題來了,檔案壓縮之後,到螢幕(On Screen Display; OSD)呈現之前它又需要解壓才能呈現,那這個過程該怎麼辦? 這又產生了一個商業策略,通常GPU製造商不會只有做GPU,它還會有自家的解壓器、顯示器等等。
他們會希望你買他們家一系列的產品,因為這些都是環環相扣的元件,需要這樣的組合,效能才能發揮到理想狀態,如果混搭其他製造商的IP,可能就會有效能不彰的問題,因為各家的壓縮和解壓演算法不同所導致。
買同一家的GPU和解壓器,可以解決上述的問題。但是如果想省成本而不想買解壓器呢? GPU是可以做解壓和檔案轉換的,但是這樣一來效率又要掉了,因為GPU又必須多做這些處理,導致到螢幕呈現的過程會變得更慢。
以上這些都是IC設計時需要考量的重點。
當IC設計藍圖完成之後,就會委託各家的IP製造商進行製造,最後才會拿到實體的IC設計電路板(我們稱之為IC回廠)。這時就會開始搭建軟體環境,例如作業系統、驅動程式、軟體框架等等。
那麼,我們要怎麼從軟體去計算GPU的效能呢?
以2D GPU來說,我們常計算的是Pixel Rate (PR),也就是GPU每秒能夠繪製多少的像素,然後再依據OSD的解析度去推算FPS。當然也有其他的測試項目,像是每秒繪製幾條線、矩形等等。另外還有就是透明度和抗鋸齒的功能,GPU在繪製半透明的圖形時,PR是多少? 混色效果是否有異常? 是否有鋸齒? 這些都是2D GPU軟體測試的幾項重點。
那麼3D GPU呢? 3D GPU除了PR之外,會去計算Texel、Triangle和Vertex。Texel主要就是GPU繪製紋理的速度,通常可能是PR效能的一半,但不一定,還是要看GPU的能力。Triangle是計算GPU可以繪製多少的三角面,由於3D模型都是用許多細小的三角面拼湊而成的,因此GPU在這個部分也是一個效能指標。再來就是Vertex,其實跟Triangle是相隨的,因為三角面是由三個頂點組合而成的,因此這是三角面的最基本元素。
除了這些之外,還有另一個數值也會量測,那就是G-Flops(每秒計算浮點數量)。有學過OpenGL或相關框架的讀者應該都知道,到了3D繪製的環節,GPU其實在處理的是大量的浮點數計算,因此G-Flops也是一項效能指標。
通常在軟體量測的時候,廠商都會給予他們的標準效能,例如會標示1 pixel/clock,也就是1個clock能產出1個pixel,而上述的指標也都會個別指出能力標準。當然了,軟體測試也存在其他因素導致效能不如預期,這個部分就已經無法細細舉例了,因此在IC驗證的環節時,就要盡量找出問題,因為在這個時候環境是相對單純的,找到效能不彰的原因會容易許多。
Last updated: